
گوگل از سیستم هوش مصنوعی جدیدی پرده برداشته که میتواند با دریافت متن تصویر خلق کند. این سیستم در واقع به کاربر اجازه میدهد تا با نوشتن یک متن توصیفی از طریق هوش مصنوعی معادل تصویری آن را ببیند. این شرکت مدعی است که مدل Imagen دارای سطح بیبدیلی از واقعگرایی و درک عمیقی از زبانهاست.
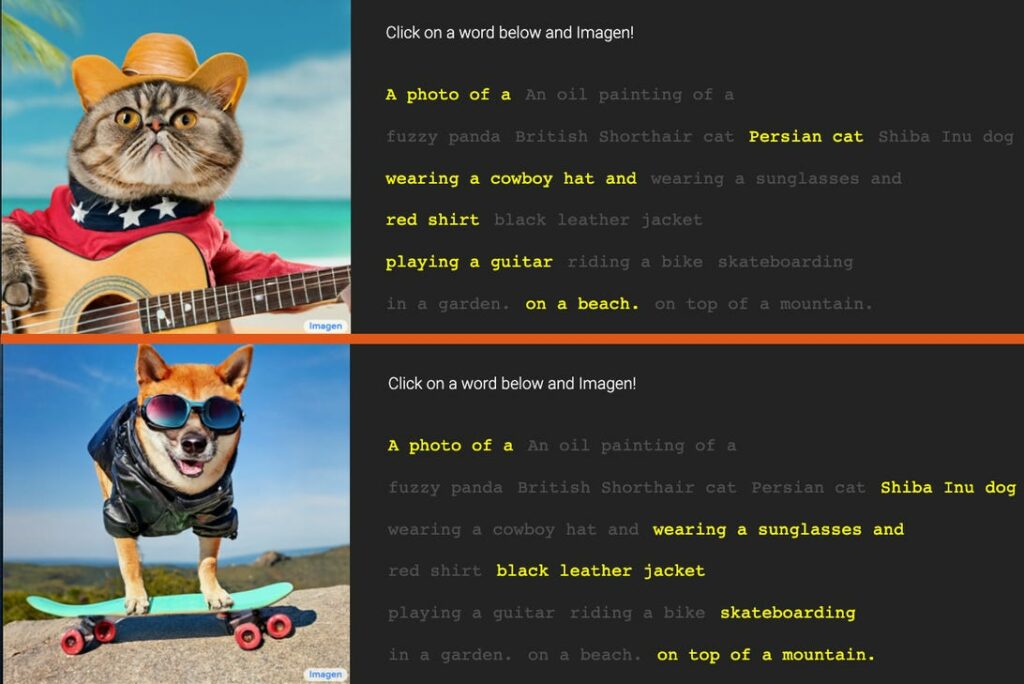
مدل هوش مصنوعی گوگل به راحتی توسط همه کاربران قابل استفاده است. برای مثال اگر بنویسید «تصویر یک گربه پرشین که کلاه گاوچرانی به سر گذاشته، پیراهن قرمز پوشیده و در ساحل گیتار میزند» تصویر زیر به دست میآید. گوگل میگوید در مقایسهای که بین مدل خود و سایر مدلهای مشابه داشته، فهمیده که کاربران دقت و صحت تصاویر را در این مدل بیشتر میپسندند.
اهالی ماونتین ویو شماری از خروجیهای مدل Imagen را در وبسایت این پروژه منتشر کردهاند. با این حال، این نمونهها دستچین شدهاند و ممکن است از بین هزاران خروجی دیگر انتخاب شده باشند که به این خوبی نیستند. مدل Imagen بهصورت عمومی در دسترس نیست، چون گوگل معتقد است که این مدل هنوز به دلایل مختلف برای استفاده عمومی آماده نیست.
هوش مصنوعی گوگل هنوز مشکلاتی دارد
مدلهای تبدیل متن به تصویر معمولا با مجموعه بزرگی از اطلاعات تعلیم داده میشوند که از سطح اینترنت به دست میآیند و دستچین نشدهاند. در نتیجه، مشکلات متنوعی به وجود میآید. محققان گوگل میگویند: «هرچند این رویکرد موجب پیشرفتهای الگوریتمی سریع در سالهای اخیر شده، دادههایی که از این طریق به دست میآیند حاوی کلیشههای اجتماعی، نظرات افراطی و توهینآمیز یا اشکالات دیگری هستند که به ضرر اقلیتها تمام میشود.»
در ادامه گفته شده: «اگرچه زیرمجموعهای از این دادهها از صافی عبور کرده بود تا نویزها و محتواهای ناخواسته را حذف کند، ولی ما از مجموعه داده LAION-400M هم استفاده کردیم که به داشتن گستره وسیعی از محتواهای نامناسب از جمله تصاویر هرزهنگاری، نژادپرستی و کلیشههای آسیبزننده اجتماعی معروف است.»
در نتیجه، Imagen سوگیریهای اجتماعی و محدودیتهای مدلهای زبانی بزرگ را به ارث برده است. با این حال، در آینده احتمالا بخشی از این مشکلات برطرف خواهند شد.